크롤링(crawling)
: 자동화된 방법으로 웹을 탐색하는 컴퓨터프로그램
인터넷 사이트의 웹페이지를 수집해서 분류하는 프로그램
스크래핑(scraping)
: 웹브라우저 화면에 표시되는 html 문서에서 사용자가 필요한 정보만 추출하여 수집하는 기술
1. 사용자가 웹브라우저의 주소창에서 url을 직접 입력한다.
2. request : 웹브라우저는 요청한 메세지를 작성해 웹서버로 전송한다.
3. response : 웹서버는 요청받은 정보를 클라이언트에게 보낸다.(HTML)
4. 웹브라우저는 응답메세지를 해석해 사용자에게 정보를 출력한다.
install.packages("rvest")
library(rvest)
html <- rvest::read_html("https://www.joongang.co.kr/article/25045987")
#read_html : R에서 주소로 request 보내고 response 받을 수 있는 함수
str_extract(html,'<title>.+</title>') #처음에 나온 하나만 출력
str_extract_all(html,'<title>.+</title>') #전부 출력
html_nodes(html,'h1')%>%
html_text()#태그정보 제외하고 text만 출력F12 화면에서
id = #
class = .
조선일보 기사 웹 스크래핑 하기
1) 특정한 뉴스 기사 검색의 url 수집
html <- rvest::read_html("https://www.joongang.co.kr/search?keyword=%EC%9D%B8%EA%B3%B5%EC%A7%80%EB%8A%A5")
url <- html_nodes(html,'h2.headline')%>%
html_nodes('a')%>%
html_attr('href')
length(url)#인코딩(encoding) ASCII문자(16진값)
인공지능 -> %EC%9D%B8%EA%B3%B5%EC%A7%80%EB%8A%A5
#디코딩(decoding)
인공지능 <- %EC%9D%B8%EA%B3%B5%EC%A7%80%EB%8A%A5
# html_attr : " " 안에 있는 문자 추출
2) 수집된 url을 이용해서 본문 뉴스 내용 수집
news <- c()
for(i in 1:length(url)){
html <- read_html(url[i])
temp <- html_nodes(html,'div.article_body.fs3')%>%
html_text()
news <- c(news,temp)
Sys.sleep(2)
}3) 수집한 기사(txt) 저장 및 불러오기
write(str_trim(news),'c:/data/news.txt') #수집한 기사 data 폴더에 저장
ai_news <- readLines('c:/data/news.txt') #불러오기[문제206] 동아일보 '인공지능' 뉴스기사 검색을 통해 본문기사 내용을 donga_ai.txt로 저장하고, 본문 뉴스 기사 내용을 명사만 추출해서 wordcloud로 시각화 해주세요. 단 뉴스 기사는 5페이지까지 수집하세요.
https://www.donga.com/news/search?p=1&query=%EC%9D%B8%EA%B3%B5%EC%A7%80%EB%8A%A5&check_news=1&more=1&sorting=1&search_date=1&v1=&v2=&range=1: 1페이지
https://www.donga.com/news/search?p=16&query=%EC%9D%B8%EA%B3%B5%EC%A7%80%EB%8A%A5&check_news=1&more=1&sorting=1&search_date=1&v1=&v2=&range=1 : 2페이지
https://www.donga.com/news/search?p=31&query=%EC%9D%B8%EA%B3%B5%EC%A7%80%EB%8A%A5&check_news=1&more=1&sorting=1&search_date=1&v1=&v2=&range=1 : 3페이지
https://www.donga.com/news/search?p=46&query=%EC%9D%B8%EA%B3%B5%EC%A7%80%EB%8A%A5&check_news=1&more=1&sorting=1&search_date=1&v1=&v2=&range=1 : 4페이지
https://www.donga.com/news/search?p=61&query=%EC%9D%B8%EA%B3%B5%EC%A7%80%EB%8A%A5&check_news=1&more=1&sorting=1&search_date=1&v1=&v2=&range=1 : 5페이지
1) url 수집
library(rvest)
url <- c()
for(i in seq(1,61,by=15)){
url_text <- paste0("https://www.donga.com/news/search?p=",i,
"&query=%EC%9D%B8%EA%B3%B5%EC%A7%80%EB%8A%A5&check_news=1&more=1&sorting=1&search_date=1&v1=&v2=&range=1")
html <- read_html(url_text)
temp <- html_nodes(html,'p.tit')%>%
html_node('a')%>%
html_attr('href')
url <- c(url,temp)
Sys.sleep(1)
}2) url 활용 본문 기사 txt 추출 및 전처리
library(xml2)
library(stringr)
news <- c()
for(i in 1:length(url)){
html <- read_html(url[i])
article <- html_nodes(html,'div.article_txt')
xml2::xml_remove(article%>%html_nodes('div'))
#xml2::xml_remove : 특정한 태그를 제거할때 사용하는 함수, 제거해서 바로 적용된다.
text <- str_trim(article%>%html_text())
text <- str_replace_all(text,'\\[서울=뉴시스\\]','')
text <- str_replace_all(text,'[^\\.]+[A-z0-9._]+@[A-z0-9._]+','')
#[^\\.]+ : .이 아닌 1개 이상의 모든 문자열(. 뒤의 모든 문자열/공백)
news <- c(news,text)
}3) 텍스트 내 쓸모없는 부분 제거
news <- str_replace_all(news,'(\r|\n)','')4) 저장 및 불러오기
write(news,'c:/data/donga_ai.txt')
ai <- readLines('c:/data/donga_ai.txt')5) 데이터 마이닝
ai <- paste(ai,collapse = ' ')
library(KoNLP)
ai_pos <- SimplePos09(ai)
library(stringr)
word <- str_match(ai_pos,'([가-힣]+)/N')[,2]
#([가-힣]+)/N : [가-힣]+/N(1열) & [가-힣]+(2열) 둘 다
word <- word[nchar(word)>=2]
word_df <- data.frame(table(word))6) 시각화
library(wordcloud2)
wordcloud2(word_df)
[문제207] 네이버 영화리뷰정보를 수집한 후 데이터 프레임으로 저장해주세요. 컬럼은 id, date, point, comment로 생성해주세요.
1) 안녕 자두야 제주도편 데이터 수집
https://movie.naver.com/movie/point/af/list.naver?st=mcode&sword=208821&target=after&page=1
https://movie.naver.com/movie/point/af/list.naver?st=mcode&sword=208821&target=after&page=13
library(stringr)
library(rvest)
library(xml2)
df <- data.frame()
review <- data.frame()
for(i in 1:13){
html <- rvest::read_html(paste0('https://movie.naver.com/movie/point/af/list.naver?st=mcode&sword=208821&target=after&page=',i))
#닉네임 추출
id <- html_nodes(html,'td.num>a')%>%
html_text()
#날짜추출
x <- html_nodes(html,'td.num')%>%
html_text()
date <- unlist(str_extract_all(x,'\\d{2}\\.\\d{2}\\.\\d{2}'))
#평점추출
point <- html_nodes(html,"div.list_netizen_score>em")%>%
html_text()
#감상평 추출
comment <- html_nodes(html,'td.title')
xml_remove(comment%>%html_nodes('a'))
xml_remove(comment%>%html_nodes('div'))
comment <- comment%>%html_text(trim=T)
df <- data.frame(id,date,point,comment)
review <- rbind(review,df)
}+) 만약 닉네임 + 날짜 추출시
unlist(str_extract_all(x,'\\w{1,}\\*{1,}\\d{2}\\.\\d{2}\\.\\d{2}'))2) 단어 수출
library(KoNLP)
pos <- SimplePos22(review$comment)
review$tagging <- sapply(pos, function(x){paste(unlist(x),collapse = ' ')})
noun <- sapply(review$tagging,function(x){str_match_all(x,'([가-힣]+)/NC')})
review$noun <- sapply(noun,function(x){paste(unlist(x)[,2],collapse = ' ')})3) 긍정단어/부정단어 구분하기
review$point <- as.integer(review$point)
review$evalution <- ifelse(review$point >=8,'긍정','부정')
positive <- review[review$evalution == '긍정','noun']
negative <- review[review$evalution == '부정','noun']
wordcloud2(data.frame(table(unlist(strsplit(positive,' ')))))
wordcloud2(data.frame(table(unlist(strsplit(negative,' ')))))
p <- data.frame(table(unlist(strsplit(positive,' '))))
n <- data.frame(table(unlist(strsplit(negative,' '))))
names(p) <- c('word','freq')
names(n) <- c('word','freq')
p$sentiment <- 'positive'
n$sentiment <- 'negative'
df<-rbind(p,n)
library(reshape2)
df_compar <- acast(df,word~sentiment,value.var = 'freq',fill=0)7) 시각화
library(wordcloud)
windows(width=10,height=10) #새로운 창 열어서 시각화
wordcloud::comparison.cloud(df_compar,colors = c('red','blue'),
title.colors = c('red','blue'),
title.bg.colors = 'white',
title.size=2,
scale=c(2,0.5))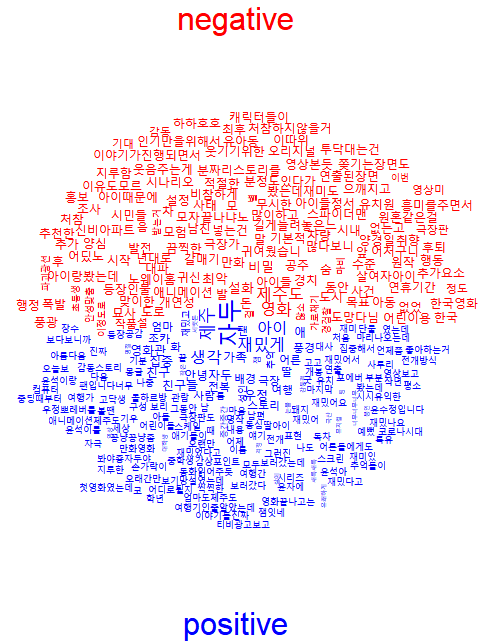
'R' 카테고리의 다른 글
| [R] web scraping - selenium (0) | 2022.02.10 |
|---|---|
| [R] web scraping - css, xpath,JSON (0) | 2022.02.10 |
| [R] 텍스트 마이닝 (0) | 2022.02.08 |
| [R] 문제풀이 (0) | 2022.02.07 |
| [R] stringr (0) | 2022.02.04 |


