library(stringr)
text <- c('sql','SQL','sql100','PLSQL','plsql','R','r','r0','python','PYTHON','pyth0n','python#',
'100','*100','*','&','^','%','$','#','@','!','~','(',')','행복','ㅋㅋㅋ','ㅠㅠㅠㅠ')대문자 S로 시작하는 벡터값 찾기
grep('^S',text,value = T)
text[str_detect(text,'^S')]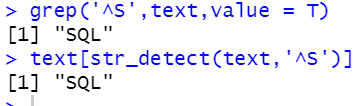
소문자 s로 시작하는 벡터값 찾기
grep('^s',text,value=T)
text[str_detect(text,'^s')]
대문자 S 또는 소문자 S로 시작하는 벡터값 찾기
grep('^[Ss]',text,value=T)
text[str_detect(text,'^[Ss]')]
대소문자로 시작(구분X)
[Ss]
grep('[Ss]',text,value=T)
text[str_detect(text,'[Ss]')]
N 또는 n으로 끝나는 벡터값(뒤에 특수문자 포함)
[Nn]
grep('[Nn]',text,value=T)
text[str_detect(text,'[Nn]')]
N 또는 n으로 끝나는 벡터값
grep('[Nn]$',text,value=T)
text[str_detect(text,'[Nn]$')]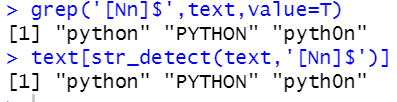
str_detect : 특정한 문자가 있는지 검사해서 TRUE,FALSE를 리턴하는 함수
str_detect(text,'SQL')
text %in% 'SQL'
grep('SQL',text,value=T)
text[str_detect(text,'SQL')]
text <- c('sqlsql','ssqls','SQLs')str_count : 주어진 단어에서 해당 글자가 몇번 나오는지를 리턴하는 함수. 대소문자 구분
str_count(text,'s') #s가 몇번 나왔는지
str_count(text,'sql')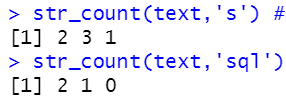
str_c : 문자열을 합쳐서 출력하는 함수(=paste0)
paste('R','빅데이터분석',sep=' ') #sep=' ' 기본값
paste0('R','빅데이터분석')
str_c('R','빅데이터분석',sep='') #sep='' 기본값
str_dup : 주어진 문자열을 주어진 횟수만큼 반복해서 출력하는 함수
str_dup('파도 소리 듣고 싶다',3)
str_length : 주어진 문자열의 길이를 리턴하는 함수
nchar("해운대 가고 싶다")
str_length("해운대 가고 싶다")
str_locate : 주어진 문자열에서 특정한 문자가 처음으로 나오는 위치를 리턴하는 함수
str_locate('january','an')
str_locate_all : 주어진 문자열에서 특정한 문자가 나오는 모든 위치를 리턴하는 함수
str_locate_all('january','a')
str_locate_all('january','a')[[1]][1]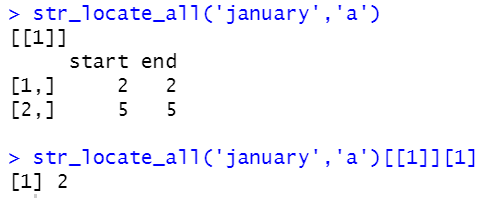
str_replace : 주어진 문자열에서 문자를 새로운 문자로 바꾸는 함수, 첫번째 일치하는 문자만 바꾼다.
sub('a','*','banana')
str_replace('banana','a','*')
str_replace_all : 주어진 문자열에서 문자를 새로운 문자로 바꾸는 함수, 일치하는 모든 문자를 바꾼다
gsub('a','*','banana')
str_replace_all('banana','a','*')
str_split : 주어진 문자열에서 지정된 문자를 기준으로 분리하는 함수
strsplit('R Developer',split = ' ')
str_split('R Developer',' ')
str_sub : 주어진 문자열에서 지정된 시작인덱스부터 끝인덱스까지 문자를 추출하는 함수
substr('RDeveloper',1,1)
str_sub('RDeveloper',1,1)
str_sub('RDeveloper',start=1,end=1)
str_sub('RDeveloper',start=1,end=5)
문자열에서 뒤에 글자를 추출하는 방법
substr('RDeveloper',nchar('RDeveloper')-2,nchar('RDeveloper'))
str_sub('RDeveloper',start = -3)
str_trim : 접두,접미부분에 연속되는 공백문자를 제거하는 함수
str_trim(' R ',side='both') #기본값
str_trim(' R ',side='left') #접두 공백문자만 제거
str_trim(' R ',side='right') #접미 공백문자만 제거
trimws(' R ')
text <- c('sql','SQL','sql100','PLSQL','plsql','R','r','r0','python','PYTHON','pyth0n','python#',
'100','*100','*','&','^','%','$','#','@','!','~','(',')','행복','ㅋㅋㅋ','ㅠㅠㅠㅠ')str_extract : 문자열에서 지정된 문자열을 찾는 함수
str_extract(text,'[[:digit:]]+')
str_extract(text,'[[:digit:]]{1,}')
unlist(str_extract_all(text,'[[:digit:]]{1,}'))
str_extract_all(text,'[[:digit:]]{1,}',simplify=T)
text <- "R is programming language PYTHON is programming language"text <- "R is programming language PYTHON is programming language"
grep('programming',text,value = T) #programming이 포함된 문장 전체 추출
x <- unlist(strsplit(text,split=' '))
grep('programming',x,value=T) #programming만 추출
str_extract(text,'programming') #문장내에서 단어를 검색할때는 처음으로 찾는 단어만 추출한다.
str_extract_all(text,'programming') #문장내에서 단어를 검색할때는 찾는 단어 모두 추출한다.
#(문장내에서 검색할때는 _all이 편함)
str_extract(x,'programming') #벡터안에서 단어를 검색할때는 위치를 추출한다
unlist(str_extract_all(x,'programming'))
data <- "R is a programming language and free software environment for statistical computing
and graphics supported by the R Foundation for Statistical Computing.[6] The R language is
widely used among statisticians and data miners for developing statistical software[7] and data
analysis.[8] Polls, data mining surveys, and studies of scholarly literature databases show
substantial increases in popularity;[9] as of January 2021, R ranks 9th in the TIOBE index,
a measure of popularity of programming languages.[10] A GNU package,[11] the official R software
environment is written primarily in C, Fortran, and R itself[12] (thus, it is partially self-hosting)
and is freely available under the GNU General Public License. Pre-compiled executables are provided
for various operating systems. Although R has a command line interface, there are several third-party
graphical user interfaces, such as RStudio, an integrated development environment, and Jupyter,
a notebook interface.[13][14]"[문제187] 첫문자가 대문자로 시작되는 단어를 찾으세요.
str_extract_all(data,'[[:upper:]]{1,}[[:alpha:]]{0,}')
str_extract_all(data,'[A-Z]+//w*')
[문제188] 숫자를 찾아주세요.
str_extract_all(data,'[[:digit:]]{1,}')
str_extract_all(data,'\\d+')
[문제189] 숫자 앞과 뒤에 있는 문자도 찾아주세요.
str_extract_all(data,'[[:alpha:]]{0,}[[:digit:]]{1,}[[:alpha:]]{0,}')
str_extract_all(data,'\\w*\\d+\\w*')
str_extract_all(data,'\\w{0,}\\d+\\w{0,}')
[문제190] 관사 a, A, the, The 함께 사용되는 단어를 출력해주세요.
str_extract_all(data,'(a|A|the|The) \\w+')
str_extract_all(data,'(a|A|the|The)\\s\\w+') #\\s : 공백문자
str_extract_all(data,'(a|A|the|The)[[:space:]]\\w+') #[[:space:]] : 공백문자
#\\s : 공백문자
#[[:space:]] : 공백문자
[문제191] 숫자 앞과 뒤에 있는 문자 또는 숫자들은 전부 공백문자로 수정한 후 text1 변수에 저장하세요.
text1 <- str_replace_all(data,'\\w{0,}\\d+\\w{0,}',' ')
[문제192] text1변수에 특수문자만 찾아주세요.
str_extract_all(text1,'[[:punct:]]')
str_extract_all(text1,'\\W')
[문제193] text1변수에 특수문자 앞과 뒤에 문자가 있는 문자를 찾아주세요.
str_extract_all(text1,'\\w+[[:punct:]]\\w+')
[문제194] 특수문자 앞과 뒤에 문자가 있는 문자를 찾아서 특수문자를 제거한 단어로 변환해주세요.
1) 특수문자 제거하면 안되는 문자 확인/변경(문제 193)
text1 <- str_replace(text1,"self-hosting","selfhosting")
text1 <- str_replace(text1,"Pre-compiled","Precompiled")
text1 <- str_replace(text1,"third-party","thirdparty")
2) 특수문자 공백문자로 변경
str_replace_all(text1,'[[:punct:]]',' ')
3) 특수문자 제거하면 안되는 문자 다시 변경
text1 <- str_replace(text1,"selfhosting","self-hosting")
text1 <- str_replace(text1,"Precompiled","Pre-compiled")
text1 <- str_replace(text1,"thirdparty","third-party")
str_extract_all(text1,'\\w+[[:punct:]]\\w+') #확인
[문제195] text1 변수에 있는 문장의 단어의 빈도수를 구하세요.
text1 <- tolower(text1)
word <- unlist(str_split(text1,' '))
word <- word[!nchar(word)==0]
df <- data.frame(table(word))
wordcloud(df$word,df$Freq,
scale=c(2,0.5),
min.freq = 1,
colors=brewer.pal(9,'Set1'),
random.order=F,
max.words=50)
[문제196] data 변수에 있는 문장에서 [숫자] 대괄호 안에 있는 숫자들을 추출해주세요.
str_extract_all(data,'\\[\\d+\\]')
[문제197] data 변수에 있는 문장에서 (문자) 괄호안에 있는 문자를 추출해 주세요.
str_extract_all(data,'\\([^)]+\\)')#^) : 문자
[문제198] data 변수에 있는 문장에서 콤마 앞에 문자와 같이 추출해 주세요.
str_extract_all(data,'\\w+,')
str_extract_all(data,'\\w+\\,')+ 변수에 있는 문장에서 . , ; 앞에 문자와 같이 추출
str_extract_all(data,'\\w+[.,;]')
str_extract_all(data,'\\w+(\\.|,|;)')'R' 카테고리의 다른 글
| [R] 텍스트 마이닝 (0) | 2022.02.08 |
|---|---|
| [R] 문제풀이 (0) | 2022.02.07 |
| [R] grep, 정규표현식(Regular Expression) (0) | 2022.02.03 |
| [R] 시각화 - wordcloud (0) | 2022.02.03 |
| [R] 시각화 문제 -barplot,ggplot (0) | 2022.01.28 |


