웹 페이지 주소가 위치정보만 가지고 있을 때(1페이지,2페이지 주소가 같을 경우)
요약 )
실제 주소를 찾는 방법
F12 -> Network ->
Preview 확인하면서 수집할 대상이 있는 Name 찾기 ->
Headers Request URL 확인 가능
+) RequestURL에 https://comment.daum.net/apis/v1/posts/149671721/comments?parentId=0&offset=0&limit=10&sort=RECOMMEND&isInitial=true&hasNext=true
offset=m limit=n : m번째부터 n개의 데이터를 출력함(JSON)
1. css 선택자 사용 방법
실제 주소 찾기
F12 -> Network ->
Preview 확인하면서 수집할 대상이 있는 Name 찾기

Headers Request URL 확인 가능 -> 우클릭 copy

library(rvest)
library(stringr)
html <- read_html("https://movie.naver.com/movie/bi/mi/pointWriteFormList.naver?code=194204&type=after&isActualPointWriteExecute=false&isMileageSubscriptionAlready=false&isMileageSubscriptionReject=false&page=1")
review <- html_nodes(html,'div.score_reple')%>%
html_text(trim=T)
review <- gsub('\n|\t|\r',' ',review) #review <- str_replace_all(review,'\n|\t|\r',' ')
review <- str_replace_all(review,'^관람객',' ')
review <- str_replace_all(review,'신고$',' ')
review <- str_trim(review)
review <- str_squish(review) #review <- gsub('\\s{2,}',' ',review)
x <- str_extract_all(review,'\\w+\\(.+\\)\\s\\d{4}\\.\\d{2}\\.\\d{2}\\s\\d{2}:\\d{2}')
id <- str_extract(x,'\\w+\\(.+\\)')
date <- str_extract(x,'\\d{4}\\.\\d{2}\\.\\d{2}\\s\\d{2}:\\d{2}')
point <- html_nodes(html,"div.star_score>em")%>%html_text()
comment <- str_replace_all(review,'\\w+\\(.+\\)\\s\\d{4}\\.\\d{2}\\.\\d{2}\\s\\d{2}:\\d{2}','')
comment <- str_replace_all(review,'[ㄱ-ㅎㅏ-ㅣ\\.,!?]',' ')
comment <- str_replace_all(review,'[^가-힣]',' ') #한글만
View(data.frame(id=id,date=date,point=point,comment=comment))
2. xpath 사용 방법
상대경로
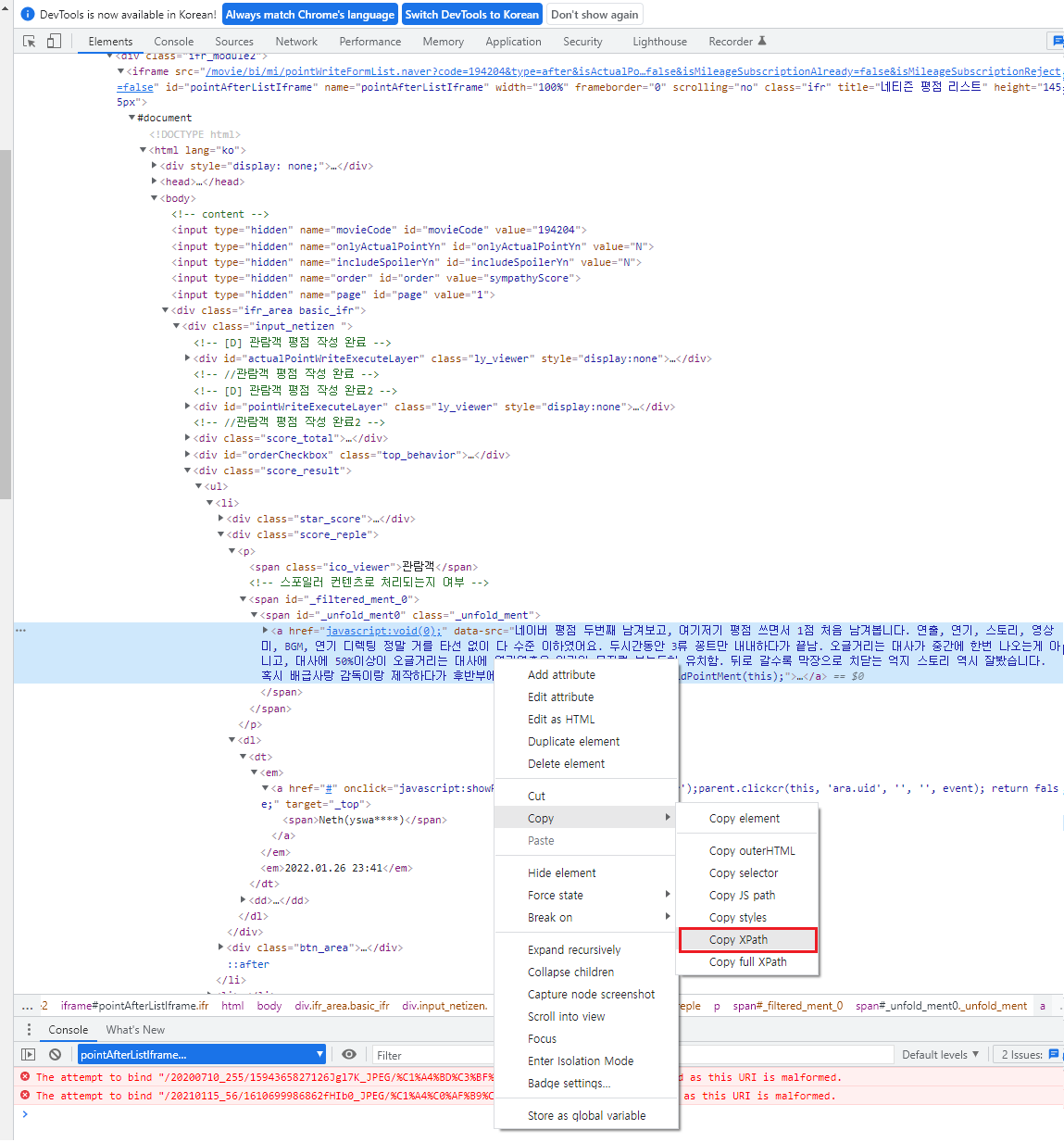
html_nodes(html,xpath='\\div[@class="star_score"]/em')
\\*[@id="unfold_ment0"]
\\*[@id="_filtered_ment_1"]/text()절대경로

id <- html_nodes(html,xpath='/html/body/div/div/div[5]/ul/li/div[2]/dl/dt/em[1]/a/span')%>%
html_text()
date <- html_nodes(html,xpath='/html/body/div/div/div[5]/ul/li/div[2]/dl/dt/em[2]')%>%
html_text()
point <- html_nodes(html,xpath='/html/body/div/div/div[5]/ul/li/div[1]/em')%>%
html_text()
comment <- html_nodes(html,xpath='/html/body/div/div/div[5]/ul/li/div[2]/p/span[2]')%>%
html_text()
# 1번째 댓글 full xpath : /html/body/div/div/div[5]/ul/li[1]/div[2]/p/span[2]
# 2번째 댓글 full xpath : /html/body/div/div/div[5]/ul/li[2]/div[2]/p/span[2][문제208] 네이버에서 영화리뷰 정보를 수집한 후, 데이터 프레임으로 저장해주세요. 컬럼은 id,date,point,comment로 생성해주세요.
1) xpath를 이용해서 데이터를 수집하세요.
movie <- data.frame()
for(i in 1:10){
html <- read_html(paste0("https://movie.naver.com/movie/bi/mi/pointWriteFormList.naver?code=194204&type=after&isActualPointWriteExecute=false&isMileageSubscriptionAlready=false&isMileageSubscriptionReject=false&page=",i))
#id
id <- html_nodes(html,xpath='/html/body/div/div/div[5]/ul/li/div[2]/dl/dt/em[1]/a/span')%>%
html_text()
#date
date <- html_nodes(html,xpath='/html/body/div/div/div[5]/ul/li/div[2]/dl/dt/em[2]')%>%
html_text()
#point
point <- html_nodes(html,xpath='/html/body/div/div/div[5]/ul/li/div[1]/em')%>%
html_text()
#comment
review <- html_nodes(html,xpath='/html/body/div/div/div[5]/ul/li/div[2]/p/span[2]')%>%
html_text()
movie <- rbind(movie,data.frame(id=id,date=date,point=point,review=review))
Sys.sleep(1)
}
View(movie)
2) 수집한 내용을 형태소 분석을 해보세요
#최적화
write.csv(movie,file='c:/data/movie_raw.csv',row.names = F)
movie$review <- str_trim(movie$review)
movie$review <- str_replace_all(movie$review,'[ㄱ-ㅎㅏ-ㅣ\\.,!?]',' ')
movie$review <- str_replace_all(movie$review,'CG|cg','그래픽')
movie$review <- str_squish(movie$review)
#형태소
library(KoNLP)
useNIADic()
pos <- SimplePos22(movie$review)
noun <- str_match_all(pos,'([가-힣]+)/NC')
noun_unique <- sapply(noun,unique) #중복 단어 제거
noun_unique[[1]][,2]
movie$noun <- sapply(noun,function(x){paste(unique(unlist(x)[,2][str_length(x[,2])>=2]),collapse = ' ')})
View(movie)
3) 평점을 기준으로 1~4 부정 5~7 중립 8~10 긍정으로 레이블을 생성해주세요.
movie$point <- as.integer(movie$point)
movie$evaluation <- ifelse(movie$point>=8,'긍정',ifelse(movie$point>=5&movie$point<=7,'중립','부정'))
View(movie)
positive <- movie[movie$evaluation=='긍정','noun']
neutral <- movie[movie$evaluation=='중립','noun']
negative <- movie[movie$evaluation=='부정','noun']
positive_df <- data.frame(table(unlist(strsplit(positive,' '))))
negative_df <- data.frame(table(unlist(strsplit(negative,' '))))
neutral_df <- data.frame(table(unlist(strsplit(neutral,' '))))
names(positive_df) <- c('word','freq')
names(negative_df) <- c('word','freq')
names(neutral_df) <- c('word','freq')
positive_df$sentiment <- '긍정'
negative_df$sentiment <- '부정'
neutral_df$sentiment <- '중립'
4) 레이블을 기준으로 명사만 compare wordcloud를 생성하세요.
df <- rbind(positive_df,negative_df,neutral_df)
library(reshape2)
df_compar <- acast(df,word~sentiment,value.var = 'freq',fill=0)
head(df_compar)
library(wordcloud)
windows(width = 10,height = 10)
wordcloud::comparison.cloud(df_compar,colors = c('blue','red','purple'),
title.colors = c('blue','red','purple'),
title.bg.colors = 'white',
title.size = 2,
scale = c(2,0.5))
+) 최대빈도 단어 추출
library(dplyr)
positive_df%>%
arrange(desc(freq))%>%
head(2)
df%>%
group_by(sentiment)%>%
mutate(rank=dense_rank(desc(freq)))%>%
filter(rank<=2)%>%
arrange(sentiment,rank)
df%>%
group_by(sentiment)%>%
mutate(rank=dense_rank(desc(freq)))%>%
filter(rank==1)%>%
arrange(sentiment,rank)%>%
print(n=100) #보고싶은 행의 수 설정3. JSON(JAVA OBJEXT NOTATION)
- 자바스크립트에서 사용하는 객체 표기 방법을 기반으로 한다.
-텍스트 데이터를 기반으로 한다.
-다양한 소프트웨어와 프로그램밍언어끼리 데이터를 교환할 때 많이 사용된다.
-페이징처리가 아니라 더보기 되어 있을 때
-offset=m&limit=n : m번째부터 n개의 데이터를 출력함
F12 -> Network ->
Preview 확인하면서 수집할 대상이 있는 Name 찾기 ->
Headers Request URL 확인 가능

RequestURL에 https://comment.daum.net/apis/v1/posts/149671721/comments?parentId=0&offset=0&limit=10&sort=RECOMMEND&isInitial=true&hasNext=true
offset=m limit=n : m번째부터 n개의 데이터를 출력함(JSON)

install.packages('jsonlite')
library(jsonlite)
json1 <- fromJSON("https://comment.daum.net/apis/v1/posts/149671721/comments?parentId=0&offset=0&limit=100&sort=RECOMMEND&isInitial=true&hasNext=true")
str(json)
j1 <- json1[,c('rating','content','createdAt')]
json2 <- fromJSON("https://comment.daum.net/apis/v1/posts/149671721/comments?parentId=0&offset=101&limit=100&sort=RECOMMEND&isInitial=true&hasNext=true")
j2 <- json2[,c('rating','content','createdAt')]
json3 <- fromJSON("https://comment.daum.net/apis/v1/posts/149671721/comments?parentId=0&offset=201&limit=100&sort=RECOMMEND&isInitial=true&hasNext=true")
j3 <- json3[,c('rating','content','createdAt')]
View(rbind(j1,j2,j3))
'R' 카테고리의 다른 글
| [R] 다나와 사이트 Web scrapling(selenium) (0) | 2022.02.15 |
|---|---|
| [R] web scraping - selenium (0) | 2022.02.10 |
| [R] 크롤링, 스크래핑 (0) | 2022.02.09 |
| [R] 텍스트 마이닝 (0) | 2022.02.08 |
| [R] 문제풀이 (0) | 2022.02.07 |


