Sys.setenv(JAVA_HOME="C:/Program Files/Java/jdk1.8.0_271")
install.packages("rJava")
library(rJava)
install.packages("openNLP")
library(openNLP)
library(NLP)NLP::annotate() : 텍스트 데이터에 주석 작업을 수행하는 함수
openNLP::Maxent_Sent_Token_Annotator() : 문장단위 주석 작업을 하는 함수
openNLP::Maxent_Word_Token_Annotator() : 단어단위 주석 작업을 하는 함수
openNLP::Maxent_POS_Tag_Annotator() : 품사를 태깅하는 함수
text <- "R is a programming language and free software environment for statistical computing and
graphics supported by the R Foundation for Statistical Computing."
text_sent <- NLP::annotate(text,openNLP::Maxent_Sent_Token_Annotator())
text_word <- NLP::annotate(text,openNLP::Maxent_Word_Token_Annotator(),text_sent)
postag <- NLP::annotate(text,openNLP::Maxent_POS_Tag_Annotator(),text_word)
POS=
NN 단수명사
NNS 복수명사
NNP 단수대명사
NNPS 복수대명사
VBN 과거진행형
VBZ 3인칭 현재형 단수동사
JJ 형용사
JJR 비교급 형용사
JJS 최상급 형용사
DT 한정사
CC 등위접속사
IN 전치사
MD 조동사
[문제214] text변수에 있는 문장에서 명사(NN),복수명사(NNS),단수대명사(NNP)를 추출해주세요.
#word만 뽑아내기(sentence 제외)
postag[postag$type=='word']
#data frame으로 만들기
postag_df <- data.frame(postag[postag$type=='word'])
str(postag_df)
#list인 features을 unlist로 변경
postag_df$features <- unlist(postag_df$features)
str(postag_df)
#'NN','NNS','NNP' 단어만 추출
pos_nn <- postag_df[postag_df$features %in% c('NN','NNS','NNP'),]
#postag 위치정보를 뽑아서 substr로 text에서 추출(반복문)
pos1 <- c()
for(i in 1:NROW(pos_nn)){
pos1 <- c(pos1,substr(text,pos_nn$start[i],pos_nn$end[i]))
}
[문제215] 미국 바이든 대통령 취임사 전문에서 명사(NN), 복수명사(NNS), 단수대명사(NNP),
복수대명사(NNPS),형용사(JJ), 비교급형용사(JJR), 최상급 형용사(JJS) 추출해서 시각화 해주세요.
library(rvest)
library(tm)
library(stringr)
Sys.setenv(JAVA_HOME="C:/Program Files/Java/jdk1.8.0_271")
library(rJava)
library(openNLP)
library(NLP)
웹 스크롤링
html <- read_html("https://www.whitehouse.gov/briefing-room/speeches-remarks/2021/01/20/inaugural-address-by-president-joseph-r-biden-jr/")
biden <- html_nodes(html,xpath='//*[@id="content"]/article/section/div/div/p')%>%html_text(trim=T)
biden <- biden[c(-1,-2,-211,-212)]
biden <- paste(biden,collapse = ' ')
NLP
biden_sent <- NLP::annotate(biden,openNLP::Maxent_Sent_Token_Annotator())
biden_word <- NLP::annotate(biden,openNLP::Maxent_Word_Token_Annotator(),biden_sent)
biden_postag <- NLP::annotate(biden,openNLP::Maxent_POS_Tag_Annotator(),biden_word)
biden_postag
biden_postag[biden_postag$type=='word']
biden_postag_df <- data.frame(biden_postag[biden_postag$type=='word'])
str(biden_postag_df)
biden_postag_df$features <- unlist(biden_postag_df$features)
str(biden_postag_df)
#특정 어근 추출
biden_pos_nn <- biden_postag_df[biden_postag_df$features %in% c('NN','NNS','NNP','NNPS','JJ','JJR','JJS'),]
biden_pos <- c()
for(i in 1:NROW(biden_pos_nn)){
biden_pos <- c(biden_pos,substr(biden,biden_pos_nn$start[i],biden_pos_nn$end[i]))
}
텍스트 전처리
grep("\\W",biden_pos,value=T)
grep("’\\w+",biden_pos,value=T)
grep("\\w+\\’s$",biden_pos,value=T)
biden_pos <- gsub("\\.","",biden_pos)
biden_pos <- gsub("(\\“|\\”)","",biden_pos)
biden_pos <- gsub("’\\w+","",biden_pos)
biden_pos <- gsub("\\–","",biden_pos)
시각화
word_biden_freq <- table(biden_pos)
library(wordcloud)
wordcloud(words = names(word_biden_freq), freq = word_biden_freq)
library(wordcloud2)
word_biden_df <- data.frame(word_biden_freq)
wordcloud2(word_biden_df)
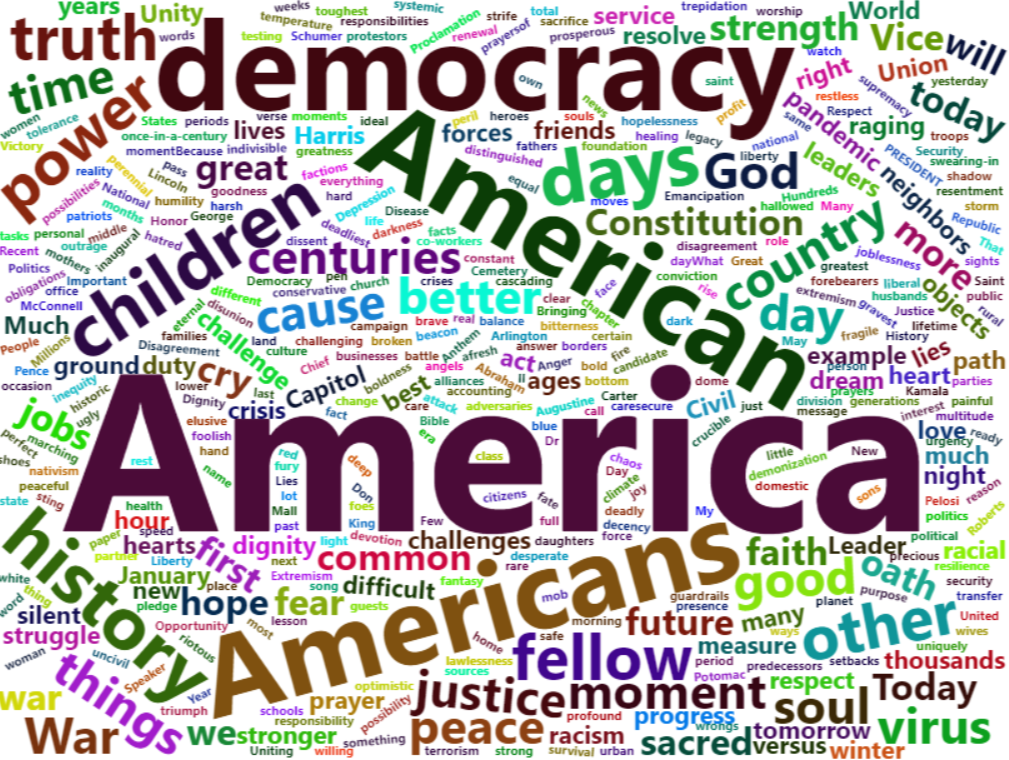
+) 비교 cloud
#명사만
biden_nn <- biden_postag_df[biden_postag_df$features %in% c('NN','NNS','NNP','NNPS'),]
word_nn <- c()
for(i in 1:NROW(biden_nn)){
word_nn <- c(biden_pos,substr(biden,biden_nn$start[i],biden_nn$end[i]))
}
#형용사만
biden_jj <- biden_postag_df[biden_postag_df$features %in% c('JJ','JJR','JJS'),]
word_jj <- c()
for(i in 1:NROW(biden_jj)){
word_jj <- c(biden_pos,substr(biden,biden_jj$start[i],biden_jj$end[i]))
}
#df만들기
nn_df <- data.frame(table(word_nn))
jj_df <- data.frame(table(word_jj))
names(nn_df) <- c('word','freq')
names(jj_df) <- c('word','freq')
nn_df$pos <- 'noun'
jj_df$pos <- 'adjective'
#합치기
nn_jj_df <- rbind(nn_df,jj_df)
nn_jj_df <- nn_jj_df[-1,]
head(nn_jj_df)
#compar 시각화
library(reshape2)
nn_jj_compar <- acast(nn_jj_df,word~pos,value.var='freq',fill=0)
comparison.cloud(nn_jj_compar)
'R' 카테고리의 다른 글
| [R] ngram, 토근화 (0) | 2022.02.18 |
|---|---|
| [R] 감성분석 예제 - 취임사 분석(군산대 감성분석사전) (0) | 2022.02.18 |
| [R] 감성분석 (0) | 2022.02.16 |
| [R] text mining (0) | 2022.02.15 |
| [R] 다나와 사이트 Web scrapling(selenium) (0) | 2022.02.15 |



