rank
오름차순 순위
x <- c(85,80,90,70,60,80,NA)
rank(x)
rank(x,na.last=T,ties.method = 'average') : rank함수 기본값

data.frame(점수=x,순위=rank(x,na.last=T,ties.method = 'first'))
: 동차일 경우 앞순서가 먼저순위
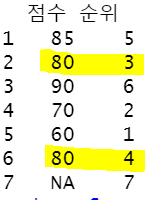
data.frame(점수=x,순위=rank(x,na.last=T,ties.method = 'last'))
: 동차일 경우 뒷순서가 먼저순위

data.frame(점수=x,순위=rank(x,na.last=T,ties.method = 'random'))
: 동차일 경우 랜덤으로 순위
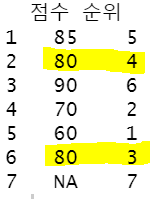
data.frame(점수=x,순위=rank(x,na.last=T,ties.method = 'max'))
: 동차일 경우 더 높은순위(4)로 동순위

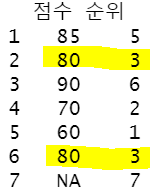
data.frame(점수=x,순위=rank(x,na.last=T,ties.method = 'min'))
: 동차일 경우 더 낮은순위(3)로 동순위
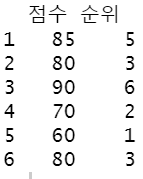
data.frame(점수=na.omit(x),순위=rank(x,na.last=NA,ties.method = 'min'))
: NA값 제거
data.frame(점수=x,순위=rank(x,na.last='keep',ties.method = 'min'))
: NA값 = NA

data.frame(점수=x,
순위_1=dplyr::min_rank(x), #NA값 = NA
순위_2=dplyr::dense_rank(x)) #연이은 순위 오름차순
내림차순 순위
rank(-x,na.last=T,ties.method = 'min')
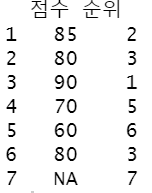
data.frame(점수=x,
순위_1=rank(-x,na.last=T,ties.method = 'min'),
순위_2=dplyr::min_rank(desc(x)),
순위_3=dplyr::dense_rank(desc(x))) #연이은 순위 내림차순
[문제142] 급여를 많이 받는 순으로 순위를 구한다음에 1등에서 5위 까지 출력해주세요. 연이은 순위를 이용하세요.
library(dplyr)
employees%>%
dplyr::mutate(rank=dplyr::dense_rank(desc(SALARY)))%>%
dplyr::filter(rank<=5)
employees$rank <- dplyr::dense_rank(desc(employees$SALARY))
employees[employees$rank<=5,][문제143] ann_sal 새로운 컬럼을 생성하세요. 값은 commission_pct NA 면 salary * 12, 아니면 (salary * 12) + (salary * 12 * commission_pct) 입력한 후 ann_sal컬럼의 값에 내림차순 기준으로 10위까지 출력해주세요.
1) 연이은 순위일 때
2) 동차를 높은순위로 할 때
1) 연이은 순위일 때
employees%>%
dplyr::mutate(ann_sal=ifelse(is.na(COMMISSION_PCT),SALARY*12,
(SALARY * 12) + (SALARY * 12 * COMMISSION_PCT)),
rank=dense_rank(desc(ann_sal)))%>%
dplyr::filter(rank<=10)employees$dense_rank <- dplyr::dense_rank(employees$ann_sal) #연이은 순위인지 확인必
employees[employees$dense_rank<=10,]2) 동차를 높은순위로 할 때
employees%>%
dplyr::mutate(ann_sal=ifelse(is.na(COMMISSION_PCT),
SALARY*12,(SALARY * 12) + (SALARY * 12 * COMMISSION_PCT)),
rank=min_rank(desc(ann_sal)))%>%
dplyr::filter(rank<=10)
employees$ann_sal <- ifelse(is.na(employees$COMMISSION_PCT),employees$SALARY*12,
(employees$SALARY * 12) + (employees$SALARY * 12 * employees$COMMISSION_PCT))employees$min_rank <- dplyr::min_rank(employees$ann_sal)
employees[employees$min_rank<=10,][문제144] 부서별 급여를 기준으로 내림차순 순위를 구하세요.
library(dplyr)
library(plyr)
df <- plyr::ddply(employees[,c('EMPLOYEE_ID','LAST_NAME','SALARY','DEPARTMENT_ID')],
'DEPARTMENT_ID',transform,순위=dplyr::dense_rank(desc(SALARY)))
library(doBy)
doBy::orderBy(~DEPARTMENT_ID+순위,df)
employees%>%
dplyr::select(EMPLOYEE_ID,LAST_NAME,SALARY,DEPARTMENT_ID)%>%
dplyr::group_by(DEPARTMENT_ID)%>%
dplyr::mutate(순위=dplyr::dense_rank(desc(SALARY)))%>%
dplyr::arrange(DEPARTMENT_ID,순위)+)SQL
select employee_id,last_name,salary,department_id,
rank() over(partition by department_id order by salary desc) 순위2,
dense_rank() over(partition by department_id order by salary desc) 순위1
from employees
order by 4,6;[문제145] JOB_ID별 급여를 많이 받는 사원 1등만 추출해 주세요.
plyr::ddply(employees[,c('EMPLOYEE_ID','LAST_NAME','SALARY','JOB_ID')],'JOB_ID',subset,
SALARY==max(SALARY))
plyr::ddply(employees[,c('EMPLOYEE_ID','LAST_NAME','SALARY','JOB_ID')],'JOB_ID',subset,
dplyr::dense_rank(desc(SALARY))==1)
employees%>%
dplyr::select(EMPLOYEE_ID,LAST_NAME,SALARY,JOB_ID)%>%
dplyr::group_by(JOB_ID)%>%
dplyr::mutate(순위=dplyr::dense_rank(desc(SALARY)))%>%
dplyr::filter(순위==1)
employees%>%
dplyr::select(EMPLOYEE_ID,LAST_NAME,SALARY,JOB_ID)%>%
dplyr::group_by(JOB_ID)%>%
dplyr::filter(dplyr::dense_rank(desc(SALARY))==1)

